
 微博
微博 微信
微信作者信息
辛海燕,贝恩公司全球专家副合伙人、大中华区高级数据分析部门负责人
DeepSeek 究竟是谁?
深度求索(DeepSeek)是一家成立于2023年的中国AI初创公司,它的迅速崛起引发了AI业界的巨大震动。依托幻方量化(管理80亿美元的量化基金)支持,仅凭不到200人的团队,抢在OpenAI公布5000亿美元“星际之门”(Stargate)项目的前一天,发布了开源模型DeepSeek R1。
DeepSeek的与众不同之处在于其出色的成本效益。该公司宣称,仅耗资600万美元、使用2000块英伟达H800图形处理器(GPU)就完成了模型训练,而GPT-4的训练成本高达8000万至1亿美元,Meta LLaMA 3更需1.6万块H100 GPU。虽非严格同类相比,却为行业成本优化打开了新思路。
DeepSeek火爆出圈,影响力席卷全球。上线数日即登顶美国应用商店免费榜,催生700余个开源衍生作品(仍在不断增长),并接入微软、AWS和英伟达AI平台。
DeepSeek的突破源于一系列工程创新,大大降低了推理成本,同时优化了训练成本。
1、混合专家(MoE)架构:少花钱,多办事
DeepSeek的混合专家(MoE)架构拥有6710亿参数,而每个词元(token)仅需激活370亿参数进行处理,在保证性能的前提下减少了算力占用。
2、知识蒸馏:让小模型“继承”大模型能力
通过优化蒸馏技术,将大模型的推理能力迁移到小模型上。采用强化学习技术,无需大规模监督微调(SFT)即可提升性能。此外,它的多头潜在注意力(MHLA)机制还将内存占用率降至传统方法的5%-13%。
3、数据优化:聪明的数据处理方式,进一步提升效率
除了模型架构创新外,DeepSeek还改进了数据处理方法。采用FP8混合精度框架进行混合/低精度计算,降低了计算成本。通过高效的奖励函数,确保将算力分配给高价值的训练数据,避免在冗余信息上浪费资源。运用稀疏化技术,使模型能够预测特定输入所需的参数,提高了速度和效率。
4、硬件优化:用最少的 GPU,做最强的计算
DeepSeek还在硬件和系统层面进行了深度优化,进一步提升了模型性能。为了尽可能地提升效率,DeepSeek开发了内存压缩和负载平衡技术。其中一大创新是绕过CUDA采用PTX编程语言,使DeepSeek工程师能够更好地控制GPU指令的执行,提高GPU利用率。此外,DeepSeek还采用DualPipe算法提升了GPU之间的通信效率,使GPU在训练过程中能够更有效地进行通信和计算。
DeepSeek改变了AI游戏规则吗?
目前看来,这些创新并不令人惊讶;事实上,它们与AI效率进化的大趋势相吻合(图1)。DeepSeek的突破性在于,一家中国的开源初创公司,竟能与头部闭源模型“掰手腕”,实现与其相媲美的性能。
1、技术创新会推动AI推理成本快速下降,DeepSeek的出现也印证了这一趋势
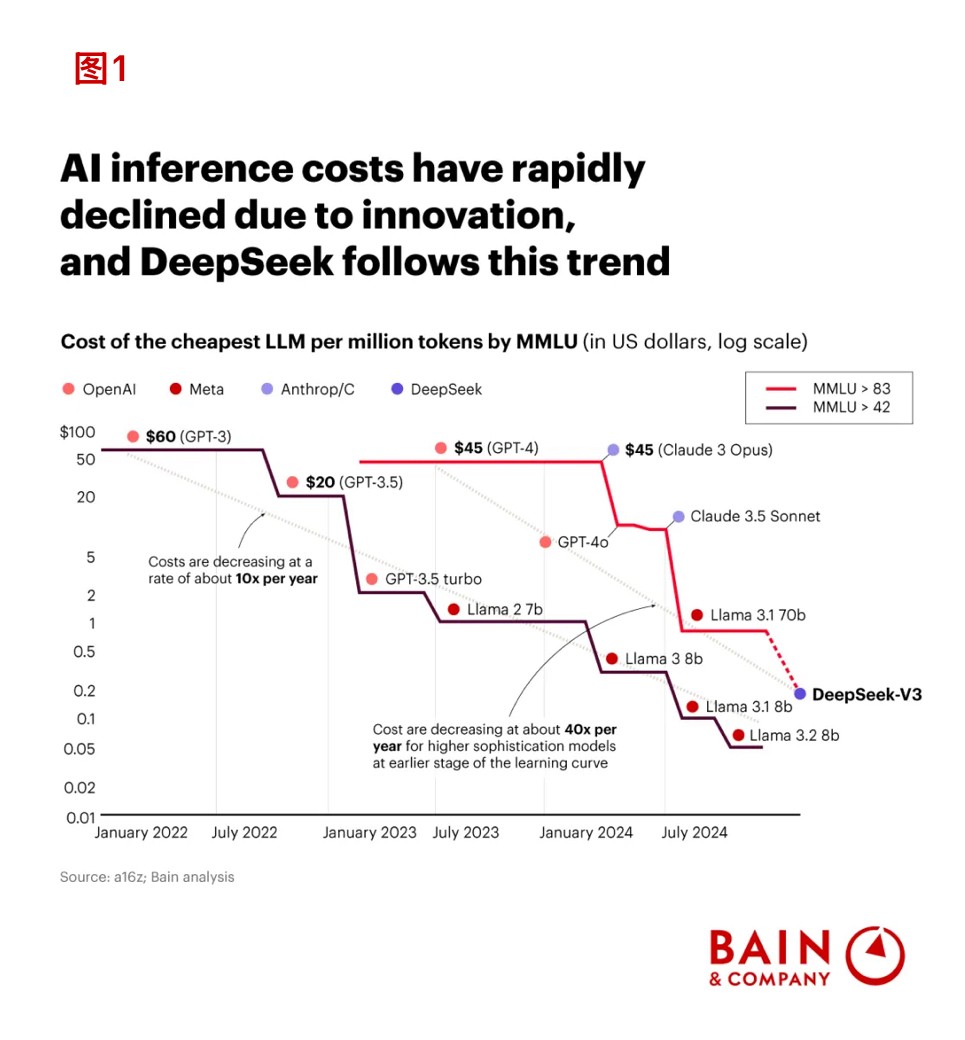
注1:成本为每百万token的最低LLM成本(美元,坐标取对数),以大规模多任务语言理解 MMLU为基准。MMLU衡量了大语言模型理解语言和解决问题的能力,依照模型提供商或通过外部评估报告结果。83分和42分是性能基准,分数越高越好。
注2:成本每年下降约10倍;在学习曲线早期,高复杂度模型的成本每年下降可达40倍
2、DeepSeek的市场影响存在多种可能性
在乐观情景下,持续的效率提升会降低推理成本,推动AI应用普及——这种模式被称为杰文斯悖论,即成本的降低反而会刺激需求的增长。尽管推理成本有所降低,但仍需投入重金推动高端训练和先进AI模型的研发,因此对尖端AI能力的研发支出仍将保持强劲。
在基础情景下,AI训练成本保持稳定,但AI推理基础架构的支出缩减30%-50%。在这种情况下,云服务商的平均资本支出将从每年800-1000亿美元降至650-850亿美元,虽然低于当前预测,但仍比2023年水平高出2-3倍。
在悲观情景下,AI训练预算收缩,推理基础架构的支出大幅下降。云服务商的平均资本支出可能降至400-600亿美元,虽然低于基础预测,但仍比2023年水平高出1.5-2倍。
3、拨开迷雾见真章
这场效率革命已经让企业董事会和领导层开始重新审视长期投资计划和战略布局。
众说纷纭之下,不妨从几点入手回归本质:
• 意料中的飞跃:推理成本持续下降是大势所趋,DeepSeek只是顺应了发展这一趋势,而非带来了颠覆性的创新。
• 切忌反应过度:AI应用普及势不可挡,只是投资步伐和形式可能会发生变化。
• 推理不是全部:领先玩家仍在竞逐下一代模型,力求开发前沿应用、开拓潜在市场。
• 各方影响不一:开源派和闭源派的竞争成为焦点。数据中心硬件在短期内面临波动,但中期仍有强劲表现。应用程序企业将从中受益。
• 能源需求影响:增速可能会略有回落,但不会很快走入平台期。
总体而言,AI需求依然坚挺。随着效率提升打开新天地,数据中心、硬件提供商和AI应用开发商将继续百舸争流、蓬勃发展。
CEO行动指南:如何应对AI成本下降的机会和AI创新迭代的挑战?
对于CEO们而言,DeepSeek事件不仅是一家公司的异军突起,更重要的是它预示着整个AI行业的前进方向。从中可以得出两点启示:AI的创新迭代迅如闪电,创新突破可能横空出世。
对此,企业管理者可采取三大策略:
• 戒急用慎,早做准备:DeepSeek的模式可能不会对AI巨头构成威胁,但它预示了AI成本会快速下降。企业需要为AI推理成本骤降做好准备,把握AI普及化带来的竞争新格局。
• 紧盯形势,尽快布局:密切关注资本支出趋势、GPU需求和AI采用率等市场信号。比如基础设施支出如果出现放缓,可能意味着效率的突破颠覆了AI经济学的底层逻辑(图2)。随着企业级AI的加速普及,企业必须尽快将AI融入核心战略中。
• 降本之外,业务创新:在降本增效之外、能够运用AI重塑核心产品的企业将成为真正的AI赢家。CEO 应推动组织不局限于自动化层面,而要将 AI 应用于产品创新、个性化客户体验乃至全新的业务模式。
